

Yedekleme (Backup): Önemli verilerin bir kopyasını düzenli aralıklarla farklı bir ortamda saklama işlemine yedekleme denir. Amaç, donanım arızası, kullanıcı hatası veya fidye yazılımı gibi siber saldırılar sonucu veri kaybını önlemektir. VMware gibi sanallaştırma platformlarında yedekleme, her sanal makinenin (VM) içindeki verileri ve durumu güvenceye almayı hedefler. Güçlü bir yedekleme stratejisi, kurumsal veri güvenliği ve iş sürekliliğinin temel taşlarından biridir.
Felaket Kurtarma (Disaster Recovery): Felaket kurtarma, büyük kesinti ve afet durumlarında sistemleri kısa sürede geri getirmeyi hedefler. Bu süreç, kritik iş uygulamalarını yeniden çalışır hâle getirmek için önceden planlanan adımlardan oluşur. Felaket kurtarma planı, yedekten geri yüklenecek sistemleri ve izlenecek süreci tanımlar. Ekip rolleri ile iletişim prosedürleri bu plan içinde yer alır.
VMware ortamlarında felaket kurtarma, birincil veri merkezindeki sanal sunucuların ikincil bir merkezde yedeklenmesini esas alır. Bu sayede sistemler kesinti anında çalışmaya devam eder. Bu sayede, ana sistemler devre dışı kalsa bile yedek altyapı devreye girerek hizmetlerin devamlılığı korunur.
VMware Ortamlarında Yedekleme İhtiyacı
İşletmeler için veri, günümüzde stratejik bir değere sahiptir. VMware sanal sunucu ortamları, bu verilerin güvenli ve yoğun biçimde işlendiği sistemlerdir. Sanallaştırma, fiziksel sunuculara göre birçok avantaja sahiptir. Buna rağmen veri kaybı riski tüm sistemler için geçerlidir.
Donanım arızaları, disk hataları, insan hataları veya kötü amaçlı yazılımlar VMware ortamlarında da veri bütünlüğünü tehdit edebilir. Bu nedenle VMware vSphere veya ESX/ESXi tabanlı altyapılarda düzenli yedekleme yapmak bir zorunluluktur. Doğru yapılandırılmış bir yedekleme sistemi, çeşitli felaket ve kesinti senaryolarında verilerin geri kazanılmasını sağlar. Buna tek bir sanal makine arızası ile tüm veri merkezini etkileyen kesintiler de dahildir.
Sanal makine yedeklemeleri, bare metal sunuculara göre daha hızlı kurtarma imkânı sağlar. Sistemler, gerektiğinde farklı bir host üzerinde hızla çalıştırılır.
Örneğin, fiziksel sunucu kurulumları genellikle saatler sürer. VMware ortamında alınan VM yedekleri ise dakikalar içinde başka bir ESX host üzerinde çalıştırılır. Bu hız ve esneklik, yedeklemenin VMware ortamlarındaki kritik önemini ortaya koymaktadır.
VMware Ortamlarında Felaket Kurtarmanın Önemi
Felaket kurtarma, bir kurumun IT altyapısının dayanıklılığını ölçer. VMware gibi yaygın sanallaştırma altyapılarında yaşanan uzun süreli kesintiler ciddi sonuçlar doğurur. Bu tür kesintiler iş kaybına, müşteri memnuniyetinin düşmesine ve itibar zedelenmesine neden olabilir.
Örneğin, saatler süren bir servis kesintisi e-ticaret siteleri için ciddi gelir kaybı demektir. Finans sektöründe veya kritik kamu hizmetlerinde ise birkaç dakikalık kesinti dahi kabul edilemez düzeyde etki yaratabilir.
VMware ortamlarında felaket kurtarma planları, kritik sanal sunucuların öncelikli olarak geri getirilmesini hedefler. Aynı zamanda veri bütünlüğünün korunması ve altyapının hızla normal operasyona dönmesi amaçlanır. Rutin yedekleme ve felaket kurtarma tatbikatları, ekiplerin hazırlıklı olmasını sağlar. Plan, felaket anında kesintisiz ve kontrollü şekilde devreye alınır.
Sonuç olarak, etkili bir felaket kurtarma planı, müşteri güvenini ve yasal uyumu destekler. Böylece kurum, beklenmeyen durumlara karşı daha güçlü bir yapıya kavuşur.
Özetle, yedekleme ve felaket kurtarma süreçleri VMware altyapılarında birbirini tamamlayan iki kritik konudur. Yedekleme anlık veri koruması sağlarken, felaket kurtarma daha büyük resme odaklanarak tüm sistemlerin çalışır halde tutulmasını amaçlar. Birlikte ele alındığında, işletmenizin her ölçekte kesintiye hazırlıklı olmasını garantilerler.

VMware Ortamlarında Yedekleme Yöntemleri ve En İyi Uygulamalar
VMware vSphere gibi sanallaştırma platformlarında yedekleme yapmak için çeşitli yöntemler ve araçlar mevcuttur. Bu bölümde, VMware ortamlarında etkili bir yedekleme stratejisi oluşturmak için teknik en iyi uygulamaları inceleyeceğiz.
Anlık Görüntüler (Snapshot) ve Yedekleme Arasındaki Fark
Snapshot (Anlık görüntü), bir sanal makinenin mevcut durumunun anlık kopyasını alır. Bu özellik, veri disklerini de kapsar ve VMware ortamlarında kullanılır.
Snapshot’lar özellikle kısa vadeli geri dönüşler için kullanışlıdır. Örneğin bir güncelleme veya konfigürasyon değişikliği öncesinde snapshot alınabilir. Böylece istenmeyen bir durumda sistem saniyeler içinde eski hâline döner.
Ancak snapshot tek başına bir yedekleme çözümü değildir. Snapshot’lar aynı host üzerinde tutulur ve uzun süreli saklanmaları disk alanını şişirerek performansı olumsuz etkileyebilir. Bu nedenle snapshot’lar geçici kullanım için tercih edilmelidir.
Kalıcı yedekleme için ise VM’nin tam kopyası özel bir yedekleme çözümüyle ayrı bir ortama alınmalıdır. Yani, snapshot, hızlı geri dönüş imkânı sunar. Yedekleme ise verinin uzun süreli ve güvenli biçimde saklanmasını sağlar. İkisi birbirini tamamlar şekilde kullanılmalı, snapshot yönetimi düzenli yapılmalıdır (eski snapshot’ları temizlemek gibi).
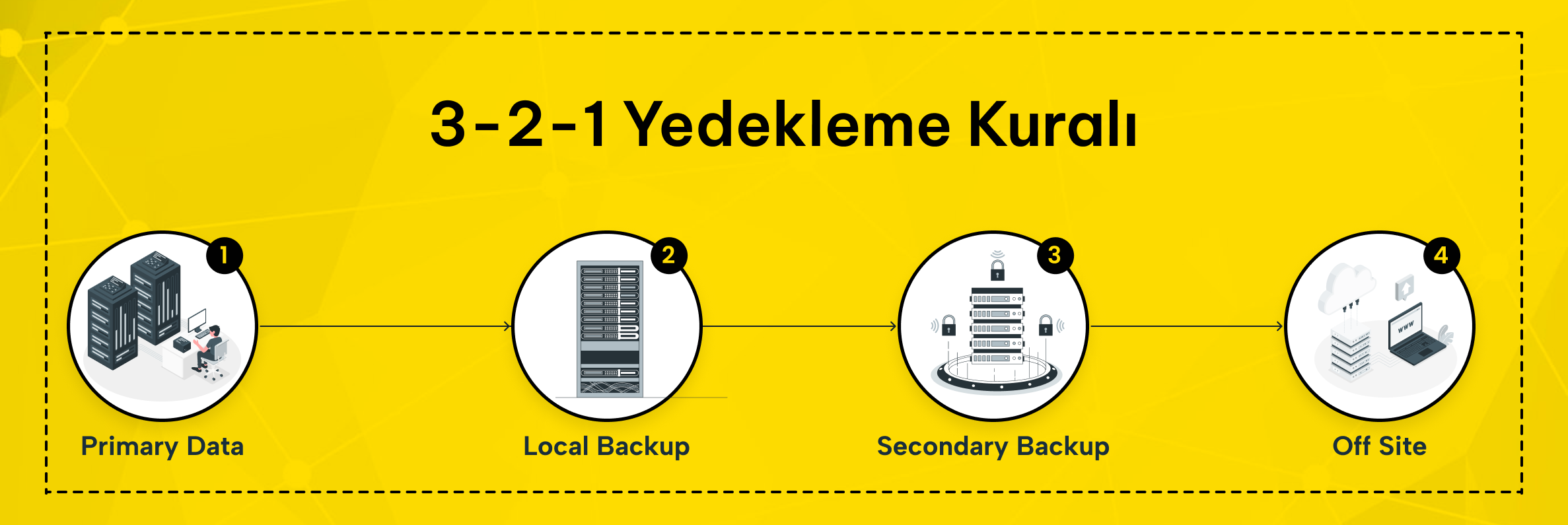
3-2-1 Kuralı ile Çok Katmanlı Yedekleme
Sağlam bir yedekleme stratejisi denildiğinde ilk akla gelen 3-2-1 yedekleme kuralıdır. Bu kural, verilerinizin en az üç kopyasının bulunmasını öngörür. Kopyalar iki farklı depolama türünde saklanmalı ve en az biri farklı bir fiziksel lokasyonda yer almalıdır.
VMware ortamlarında 3-2-1 kuralı kapsamında bir yedek yerel yedekleme sunucusunda saklanabilir. Diğer yedek ise bulut depolama ya da farklı bir veri merkezinde konumlandırılır. Bu sayede tek bir arıza veya felaket tüm kopyaları yok edemez.
Off-site yedekleme özellikle doğal afet veya şehir çapında kesintilerde hayati önem taşır. Bir şehirdeki veri merkezinizi etkileyen deprem gibi bir durumda, farklı bölgede tutulan yedekler sayesinde verilerinize ulaşırsınız.
3-2-1 kuralını desteklemek için VMware ortamlarında yedeklemeleri yapılandırırken birden fazla hedef belirleyin. Örneğin, yedekleme yazılımı kullanarak her gece yerel depolamaya ve haftada bir kez bulut deposuna yedek almak gibi.
Modern yedekleme araçları (Veeam, Nakivo, VMware Data Protection vb.), birden fazla hedefe yedekleme yapmayı destekler. Bu işlem eşzamanlı veya ardışık şekilde gerçekleştirilir. Yedeklerin şifrelenmesi ve aktarım sırasında güvenli protokollerin kullanılması önemlidir. Bu yaklaşım, özellikle dış ortamlara gönderilen yedekler için gereklidir.
Yedeklerin hava boşluğu (air-gap) bulunan veya değişmez (immutable) depolama alanlarında saklanması iyi bir uygulamadır. Bu yaklaşım, fidye yazılımlarına karşı ek koruma sağlar. Örneğin, haftalık yedeğinizi yazma korumalı bir bulut depolama alanına gönderip orada kilitlemek, saldırganların yedeklerinizi şifrelemesini önler.
Artımlı ve Tam Yedeklemeler (Performans ve Depolama İpuçları)
Tam yedekleme (Full backup), bir sistemin tamamının tek seferde yedeklenmesidir. VMware ortamında tam yedekleme, ilgili sanal makinenin tüm sanal disklerini ve ayarlarını içerir. Bu yedekleme türü, geri dönüş sırasında hızlı ve kapsamlı bir kurtarma sağlar. Ancak uygulanması zaman alır ve ek depolama alanı gerektirir.
Artımlı yedekleme (Incremental backup) ise, bir önceki yedekten bu yana değişen verileri yedekler. VMware’ın Changed Block Tracking (CBT) gibi özellikleri sayesinde artımlı yedeklemeler oldukça verimli hale gelmiştir. Sanal makinenin sadece değişen blokları yakalanarak yedekleme süresi ve boyutu ciddi oranda azaltılır.
En iyi uygulama, ilk etapta bir tam yedek alıp devamında düzenli artımlı yedeklemeler yapmaktır. Örneğin, haftalık tam yedek, günlük artımlı yedek takvimi gibi. Bu sayede sık aralıklarla yedek alınarak veri kaybı riski azaltılır. Aynı zamanda ağ ve depolama yükü kontrol altında tutulur.
Yedekleme sıklığını belirlerken sistemin değişim hızını ve RPO (Recovery Point Objective) hedefinizi göz önüne alın. Kritik verilerin sık değiştiği sistemlerde günlük yedekleme yeterli olmayabilir. Veri kaybı riskini azaltmak için dört saatlik artımlı yedekleme tercih edilebilir. Bu durumda artımlı yedeklemelerin düşük kaynak tüketimi avantajı öne çıkar.
Diferansiyel yedekleme de (her zaman son tam yedekten bu yana değişenleri alır) bir diğer yöntemdir. Artımlı yedeklemeye kıyasla geri yükleme sırasında orta seviyede hız ve güvenlik sunar.
Ayrıca yedekleme işlemlerini VMware ortamında iş yükü yoğun olmayan saatlere denk getirmek önemlidir. Genellikle gece saatleri veya hafta sonu, yedekleme penceresi için idealdir. Bu sayede çalışan sanal makinelerin performansı mesai saatlerinde etkilenmez.
Yedekleme işlemlerinde VMware vStorage APIs for Data Protection (VADP) kullanımı yaygındır. API, VMware ortamlarında tutarlılığı koruyarak hızlı yedekleme imkânı sunar. Yedekleme yazılımınızın VADP desteği olduğundan emin olun ve mümkünse uygulama tutarlı yedeklemeler yapın (Application-aware backup).
Örneğin bir veritabanı sunucusunun yedeği alınırken tutarlı bir nokta hedeflenmelidir. Bunun için yedekleme aracı veritabanını kısa süreli duraklatabilir veya transaction log kaydını kullanabilir. Bu, geri yükleme yapıldığında verinin çalışır ve sağlam olmasını garantiler.
Yedekleme Testleri ve Veri Kurtarma Doğrulaması
Bir yedeğin gerçekten işe yarayıp yaramadığının tek kanıtı, o yedekten başarılı bir geri dönüş yapılmasıdır. Bu nedenle “Yedekler, geri dönüş yapılabildiği sürece değerlidir” prensibi akıldan çıkarılmamalıdır. En iyi uygulamalardan biri, yedeklemelerin düzenli aralıklarla test edilmesidir.
Örneğin, kritik sanal makinelerin haftalık yedeklerinden birini alıp izole bir test ortamında geri yüklemeyi deneyin. Bu süreç, yedeğin bozuk olup olmadığını ve tüm verileri içerip içermediğini gösterir. Uygulamaların yedekten çalışabilir olduğu da bu aşamada doğrulanır.
Bir hata veya eksik varsa bu durum önceden tespit edilebilir. Böylece gerçek bir felaket anında değil, daha erken aşamada düzeltme yapılır.
VMware ortamları, test geri yüklemeleri kolaylaştıracak araçlara sahiptir. Bazı yedekleme yazılımları, SureBackup veya sandbox (kum havuzu) ortamlarında geri dönüş testleri sunar. Bu sayede yedekler ağdan izole edilmiş bir sanal ağ üzerinde çalıştırılarak test edilebilir. Böylece üretim ağınıza etki etmeden yedekleri doğrulamanız mümkün.
Uzmanlar, yedeklerin en az ayda bir kez rastgele seçilerek test edilmesini önermektedir. Ayrıca felaket kurtarma planları kapsamında, belirli periyotlarla tam kapsamlı kurtarma tatbikatları yapılmalıdır (örn. 6 ayda bir tüm sistemi yedekten ayağa kaldırma testi). Bu tatbikatlar, hem teknik sorunları ortaya çıkarır hem de ekiplerin olası bir acil durumda hazır olmasını sağlar.
Yedekleme testleri sırasında karşılaşılan sorunlar, yedekleme stratejinizi geliştirmek için önemli ipuçları sunar. Örneğin, bir test geri yükleme sırasında uygulamanın veritabanında tutarsızlık tespit edilebilir. Bu durumda daha sık yedekleme veya uygulama düzeyinde ek yedekleme yöntemleri (örneğin SQL dump) tercih edilebilir.
Uzun geri yükleme süreleri, yedekleme yaklaşımının yeniden ele alınmasını gerektirebilir. Daha hızlı depolama veya ağ kapasitesi bu noktada çözüm sunabilir.
Son olarak, yedekleme loglarının takibi de önemlidir. Yedekleme işlemlerinin her gün başarılı tamamlandığını doğrulamak, başarısız yedeklemeleri hızlıca yeniden çalıştırmak veya sorunu düzeltmek gerekir. VMware vCenter ile entegre çalışan yedekleme araçları, merkezi izleme ve raporlama sunar. Bu panelleri veya e-posta bildirimlerini kullanarak yedekleme süreçlerinizin sorunsuz devam ettiğinden emin olun.
VMware Ortamlarında Felaket Kurtarma Planlaması
Yedeklemeler tek başına iş sürekliliği için yeterli değildir. Asıl sınav, büyük bir kesinti yaşandığında sistemlerin ne kadar hızlı toparlandığıdır. Felaket kurtarma planlaması, bu toparlanma sürecinin önceden kurgulanması demektir. VMware ortamlarında felaket kurtarma planı hazırlarken teknik altyapıyı, iş ihtiyaçlarını ve insan faktörünü göz önünde bulundurmak gerekir.
Felaket Kurtarma Planı Nasıl Oluşturulur?
Etkili bir felaket kurtarma planı oluşturmak için öncelikle risk analizi ve kritik sistemlerin belirlenmesi ile başlanır. Şirketinizi tehdit edebilecek senaryoları listeleyin: donanım arızası, elektrik kesintisi, siber saldırı (ör. ransomware), doğal afetler vb. Ardından her bir senaryonun hangi sistemleri etkileyeceğini ve işinizi aksatma potansiyelini değerlendirin.
VMware ortamında muhtemelen birden fazla sanal sunucu farklı iş yüklerini barındırır. Bu sanal makineler arasından kritik olanları tespit edin.
Örneğin, bir e-ticaret şirketinde veritabanı sunucusu en kritik VM’ler arasında yer alır. Raporlama sunucuları ise genellikle daha düşük önceliğe sahiptir. Bu önceliklendirme, felaket anında hangi sistemlerin önce kurtarılacağını belirler.
Ardından, yedekleme stratejisi ve off-site saklama plan dahilinde netleştirilmesi gerekir. Yedeklemeler felaket kurtarma planının kalbidir; o yüzden 3-2-1 kuralı gibi en iyi uygulamaları burada devreye alın.
Kritik VM’ler için uygun yedekleme sıklıkları belirleyin. Yedeklerin en az bir kopyasının coğrafi olarak farklı bir lokasyonda tutulduğunu doğrulayın. VMware ortamlarında coğrafi yedekleme, sanal makinelerin ikincil bir lokasyona sürekli kopyalanmasına dayanır. Bu yaklaşım vSphere Replication gibi araçlarla uygulanır.
Roller ve sorumlulukların tanımlanması, planın başarıyla uygulanması için kritik önemdedir. Bir felaket durumunda kimlerin hangi adımları atacağı önceden belirlenmelidir. Örneğin:
- Felaket Kurtarma Ekibi Lideri: Kriz durumunda koordinasyonu sağlar, kararları verir ve ekibi yönetir.
- Sistem Yöneticileri: VMware altyapısındaki sunucuları yedekten geri yükler, gerekli ayarları yapar ve çalışır hale getirir.
- Ağ Uzmanları: İhtiyaç halinde ağ trafiği DR sitesine aktarılır. DNS kayıtları güncellenir ve VPN ile NSX ayarları gözden geçirilir.
- Uygulama Ekibi: Uygulama sunucularının tutarlı şekilde ayağa kalktığını, veri tutarlılığını ve entegrasyonları kontrol eder.
- İletişim Ekibi: Hem iç hem dış paydaşlara (çalışanlar, müşteriler, tedarikçiler) uygun kanallardan durum bilgilendirmesi yapar. Örneğin, müşterilere e-posta veya sosyal medya ile servis durumu hakkında bilgi vermek gerekebilir.
Bu şekilde herkesin rolü önceden tanımlı olursa, gerçek bir felaket anında kaos yaşanmaz ve herkes görevine odaklanır. VMware ortamlarında vCenter Server kritik bir bileşendir. Bu nedenle planınızda vCenter yedeğinin veya yapılandırma yedeklerinin alınması yer almalıdır. Gerekli durumlarda farklı bir sunucuda yeniden kurulum yapılmalıdır.
RPO ve RTO Hedeflerinin Belirlenmesi
RPO (Recovery Point Objective) ve RTO (Recovery Time Objective) kavramları, felaket kurtarma planının teknik hedeflerini ortaya koyar. RPO, bir felaket durumunda kabul edilebilir maksimum veri kaybı süresidir. Yani sistemler tekrar ayağa kalktığında veriler en fazla ne kadar geriden (hangi zaman noktasından) yüklenebilir.
RPO’su 4 saat olan bir veritabanında maksimum veri kaybı süresi 4 saattir. Sistem, bu süreden daha eski bir noktaya dönmeyi hedeflemez. RTO ise sistemlerin tekrar çalışır hale gelmesi için hedeflenen maksimum süredir. Örneğin RTO 2 saat ise, felaket anından itibaren 2 saat içinde kritik servislerin yeniden çalışması hedeflenir.
VMware ortamlarında RPO ve RTO değerleri, yedekleme sıklığınızı ve replikasyon stratejinizi doğrudan belirler. Eğer RPO’nuz çok düşük (örneğin birkaç dakika) ise, klasik günlük yedeklemeler yeterli olmayacaktır. Bunun yerine yakın süreli eşzamanlı replikasyon veya sürekli veri koruması gerekir.
VMware’in vSphere Replication aracı, 1 dakikaya kadar düşebilen RPO değerleri sunabilir. Yani her 1 dakikada bir sanal makine değişimlerini diğer site’a kopyalayabilir. Bu, finans kurumları gibi neredeyse sıfıra yakın veri kaybı hedefleyen yerler için idealdir.
RTO kapsamında hedef süreye tüm geri dönüş adımları dahildir. Bunlar arasında sunucuların yeniden başlatılması, ağ yönlendirmeleri ve uygulama kontrolleri yer alır. VMware Site Recovery Manager gibi otomasyon araçları kullanılarak RTO dakikalar seviyesine çekilebilir (manuel işlemler azalacağı için).
RPO/RTO hedeflerini belirlerken her bir iş yükü için ayrı değerler atanabilir. Örneğin:
- Kritik Müşteri Veri Tabanı: RPO değeri 5 dakika, RTO değeri ise 30 dakikadır. Bu seviyeler, çok kritik sistemler için neredeyse anlık replikasyon ve hızlı failover gerektirir.
- E-posta Sunucusu: RPO 1 saat, RTO 2 saat (kritik ama kısa kesintiler tolere edilebilir).
- Dosya Sunucusu/Test Sunucuları: RPO 24 saat, RTO 1 gün (daha az kritik, günlük yedek yeterli).
Bu önceliklendirmeye göre yedekleme ve felaket kurtarma kaynaklarınızı etkin kullanmanız mümkün. Yüksek öncelikli VM’ler gelişmiş koruma seviyeleriyle güvence altına alınır. Düşük öncelikli sistemler için ise daha temel yedekleme ve kurtarma yaklaşımları yeterli görülür.
Unutmayın, RPO değeri doğrudan yedekleme sıklığınızla ilişkili, RTO ise plan ve altyapı kalitenizle ilişkili bir hedeftir. Gerçekçi ancak iş ihtiyaçlarını karşılayan hedefler belirlemek ve bu hedeflere ulaşıp ulaşmadığınızı periyodik testlerle doğrulamak gereklidir.
Replikasyon ve Off-site Felaket Kurtarma Merkezleri
VMware ortamlarında en güçlü felaket kurtarma yaklaşımlarından biri, veri merkezi replikasyonu kullanmaktır. Replikasyon, birincil site verilerinin ve sanal makinelerin ikincil bir sitede sürekli kopyalanmasını sağlar. Böylece felaket kurtarma için hazır bir ortam oluşturulur. Bu sayede ana site tamamen devre dışı kalsa bile ikinci lokasyondaki kopyalar üzerinden sistemleri çalıştırmanız mümkün olur.
Replikasyon, yedeklemeden farklı olarak sürekli bir süreçtir ve genellikle daha kısa RPO sağlar. İki temel replikasyon yöntemi: Senkron ve Asenkron replikasyon.
- Senkron Replikasyon: Her veri yazma işlemi eş zamanlı olarak iki lokasyona birden yazılır. Yani bir VM diskine bir veri yazıldığında, işlem tamamlanmadan diğer site’a da aktarılır. Bu yöntemle sıfıra yakın veri kaybı (RPO ~ 0) hedeflenebilir çünkü iki taraf hep aynı kalır.
VMware’in metro cluster çözümleri veya vSAN Stretched Cluster gibi teknolojileri senkron replikasyona örnek verilebilir. Ancak coğrafi mesafe arttıkça senkron replikasyon zorlaşır. Yakın mesafedeki iki veri merkezi arasında (örneğin aynı şehir) senkron yöntem kullanılabilir. - Asenkron Replikasyon: Veriler belirli bir gecikme ile ikinci site’a iletilir. Birincil lokasyonda işlem tamamlandıktan sonra, veriler kuyruklanıp karşı tarafa gönderilir. Bu yöntemde tipik RPO değerleri birkaç dakikadan birkaç saate kadar olabilir, ayarlara bağlıdır.
Uzak mesafeli veya internet üzerinden yapılan replike işlemler genelde asenkron olur. Avantajı, birincil sistem performansına fazla yük bindirmeden replikasyon yapmasıdır. Dezavantajı ise, felaket anında en son senkronize olmadığı birkaç dakika/saat verinin kaybolmasıdır.
VMware ortamlarında Site Recovery Manager (SRM) gibi araçlar, replikasyonla felaket kurtarmayı entegre yönetmenizi sağlar. SRM, vCenter ile birlikte çalışarak felaket anlarında merkezi bir kontrol sağlar. Tanımlı kurtarma planlarına göre sanal makineler karşı sitede sıralı biçimde başlatılır.
Örneğin, otomasyon senaryoları ile sunucular belirli bir sırayla başlatılabilir. Önce Active Directory ve DNS, ardından veritabanları ve en son uygulama sunucuları devreye alınır.
Bu tür otomatik failover araçları, felaket anında müdahale süresini kısaltır. Aynı zamanda insan kaynaklı hataların önüne geçilmesine yardımcı olur. Ayrıca SRM yardımıyla planlı testler yapmak da kolaylaşır. SRM, test modunda karşı site’i yükseltip asıl site çalışmaya devam ederken bir tatbikat yapmanıza izin verir.
Bir felaket kurtarma merkezi oluştururken, orada yeterli kaynak olduğundan emin olun. Yani, replikasyon ile oraya gönderdiğiniz VM’leri çalıştıracak CPU, bellek, depolama ve ağ kapasitesi hazır bulunmalı.
Genelde DR merkezi, üretim ortamıyla aynı ölçeklerde tasarlanır ki tüm kritik işler orada da çalışabilsin. Tabii ki maliyetler nedeniyle bazı firmalar DR sitesini daha düşük kapasiteli kurar. Ayrıca sadece en kritik servisleri orada ayakta tutmayı planlar. Bu da bir stratejidir ancak bu durumda felaket anında hangi servislerden vazgeçileceği önceden belirlenmelidir.
Network yapılandırması da replikasyon stratejisinin ayrılmaz parçasıdır. VMware NSX gibi ağ sanallaştırma çözümleri burada büyük avantaj sağlayabilir. NSX kullanarak şirket içi ağ yapısını tanımlamak ve aynı yapıyı DR sitesinde oluşturmak mümkündür.
Örneğin, NSX kullanılarak üretim ortamındaki ağ ayarları diğer site’e taşınabilir. Böylece felaket anında IP adresleri ve güvenlik politikaları aynı şekilde korunur. Bu, failover olduğunda uygulamaların sanki aynı veri merkezindeymiş gibi çalışmaya devam etmesine olanak tanır. IP değişikliği gerekmez, böylece uygulama konfigürasyonları ve kullanıcı bağlantıları sorunsuz devam eder.
NSX yoksa DR sitesinde benzer bir ağ segmenti oluşturulması gerekir. Felaket anında kullanıcılar DNS üzerinden bu site’e aktarılabilir.
Özetle, replikasyon tabanlı felaket kurtarma, VMware ortamlarında iş sürekliliğini sağlamanın güçlü bir yoludur. Yedekleme veri güvenliği için vazgeçilmezdir. Anlık replikasyon ve hazır altyapı sayesinde kesintiler kullanıcılar tarafından neredeyse hissedilmez. Ancak bu çözümler ciddi planlama, yatırım ve uzmanlık gerektirir – dolayısıyla şirketinizin ihtiyacına uygun seviyede bir çözüm seçmelisiniz.
Ağ Yapılandırması ve VMware NSX ile Süreklilik
Bir felaket kurtarma planının başarıya ulaşması için ağ sürekliliğinin sağlanması kritik rol oynar. Sadece sunucuları başka bir lokasyonda çalıştırmak yetmez; kullanıcıların ve sistemlerin bu sunuculara erişimi de kesintisiz olmalıdır. VMware ortamlarında felaket kurtarma yaparken şu ağ konularına dikkat edilmelidir:
- IP Adresleme ve DNS: DR sitesinde çalışacak sunucular için IP planınız olmalı. İki temel yaklaşım bulunur. DR senaryosunda IP adresleri üretimle aynı tutulabilir. Farklı bir IP bloğu kullanıldığında ise geçiş DNS kayıtlarının güncellenmesiyle sağlanır.
İlk yaklaşım anlık geçiş sağlar ancak kurulum karmaşıktır. İkinci yaklaşım daha basit ama geçişte birkaç dakikalık DNS yayılma gecikmesi olabilir. - VPN ve Güvenlik Duvarı: VPN bağlantıları kullanan yapılarda DR senaryosu ayrıca planlanmalıdır. Kesinti durumunda VPN trafiği DR merkezine yönlendirilir. Ağ ekipleri, felaket anında VPN uç noktalarını değiştirmek veya aktif/aktif konfigürasyon kurmak gibi planlar yapmalıdır.
Uygulamaların çalışmaya devam edebilmesi için DR sitesinde güvenlik duvarı kuralları ve ACL’ler üretimle tutarlı olmalıdır. Aksi durumda iletişim sorunları yaşanabilir. - NSX ile Ağ Sanallaştırma: VMware NSX, ağ sanallaştırma ve mikro segmentasyon sağlayan bir platformdur. Felaket kurtarma senaryosunda NSX kullanımı, hem işleri kolaylaştırır hem de hızlandırır.
Örneğin, Cross-vCenter NSX yapılandırması, veri merkezleri arasında L2 stretching imkânı sunar. Aynı ağlar bu sayede her iki lokasyonda da aktif kalır. Bu sayede sanal makine DR sitesinde çalışmaya başladığında IP adresini değiştirmeye gerek kalmaz. Aynı L2 ağının DR ortamında da bulunması bu durumu mümkün kılar. NSX, dağıtılmış güvenlik duvarı ve yönlendirme yetenekleriyle uygulamalar arası trafik kurallarının DR ortamında korunmasına yardımcı olur.
Kısacası NSX, network katmanını sanallaştırarak altyapıyı esnek hâle getirir. Ağlar ve güvenlik ayarları bu yapı sayesinde sunucularla birlikte taşınabilir. Bu da felaket kurtarma süresini ve karmaşasını ciddi ölçüde azaltır. - Yük Dengeleme ve Yüksek Erişilebilirlik: Aktif/aktif çalışan uygulamalarda Global Load Balancing (GLB) tercih edilebilir. Bu yapı, veri merkezleri arasında kesintisiz trafik yönetimi sağlar. Her iki tarafta çalışan sunucular arasında trafik dağıtımı yapılabilir. Bu dağıtım, coğrafi DNS yönlendirmesi veya bulut tabanlı global load balancer servisleriyle sağlanır.
Bu durumda felaket kurtarma, sadece tek tarafın yükünü diğerine aktarmak kadar basit hale gelir. VMware’in HCX gibi çözümleri de uygulama mobilitesini ve network uyumluluğunu artırmaya yönelik kullanılabilir.
Sonuç olarak, felaket kurtarma planı hazırlarken ağ katmanı için ayrıntılı senaryolar oluşturulması gerekir. Sadece sunucuları yedeklemek yeterli değil; o sunucuların kullanılabilir olması için ağınızın da hazır olması gerekir. VMware NSX gibi modern araçlar sayesinde bu süreç artık daha kolay yönetilir. Aynı zamanda otomasyon seviyesi önemli ölçüde artar.
Düzenli DR Testleri ve Plan Güncellemeleri
Hiçbir felaket kurtarma planı, onu test etmediğiniz sürece gerçekten “çalışır” kabul edilemez. Bu nedenle düzenli DR (Disaster Recovery) testleri yapılması en kritik operasyonel en iyi uygulamalardan biridir. Testler, planınızın zayıf noktalarını barış zamanında ortaya çıkarır, böylece gerçek bir felakette bu hatalar yaşanmaz. VMware ortamında DR testi yapmanın birkaç yolu vardır:
- Masa Başı Tatbikat (Paper Drill): Ekip üyeleriyle bir araya gelip felaket senaryosunu kağıt üzerinde yürütmek. Bu, herkesin rollerini tazelemesi ve olası eksik adımları fark etmek için iyi bir başlangıçtır.
- Kısıtlı Kapsamlı Test: Gerçekten bazı sanal makinelere müdahale ederek yapılan testler. Örneğin, üretim ortamındaki bir test VM’ini kapatıp DR sitesindeki kopyasından çalıştırmayı denemek. Veya bir uygulama grubunu (web + db sunucuları gibi) DR’da ayağa kaldırıp, kullanıcıların erişimini simüle etmek. VMware SRM kullanıyorsanız, “Test Failover” özelliğiyle, canlı sisteme etki etmeden DR prosedürünü prova edebilirsiniz.
- Tam Kapsamlı Test: Yıllık veya altı ayda bir yapılabilecek, mümkünse üretime yakın bir tatbikat. Bu, hafta sonu veya planlı bakım zamanında yapılır. Tüm sistemlerin yedeği alındıktan sonra ana site devre dışı bırakılır.
DR sitesi, gerçek bir felaket senaryosu varmış gibi aktif hâle getirilir. Bu test oldukça zorludur ancak en gerçekçi sonucu verir.
Testler sonucunda elde edilen bulgular altın değerindedir. Örneğin, test sırasında fark edersiniz ki DR sitesinde belirli bir lisans sunucusu çalışmadığı için bazı uygulamalar açılmıyor. Bu, planınıza “lisans sunucusunun da replikasyonu veya yedeği olmalı” şeklinde bir madde eklemenizi gerektirir.
Test sırasında belirli bir sunucunun 15 dakikada açıldığı görülebilir. Bu durum RTO hedefini etkiler ve sunucunun geliştirilmesi ya da önceliğinin değiştirilmesi gündeme gelebilir.
Plan Güncellemeleri: IT altyapınız yaşayan bir yapıdır; dolayısıyla felaket kurtarma planınız da yaşayan bir doküman olmalıdır. Yeni sunucular eklendikçe, varolanlar emekliye ayrıldıkça, uygulamalarda değişiklikler oldukça planı güncellemeniz gerekir.
Örneğin, VMware ortamına eklenen her kritik VM yedekleme kapsamına alınmalıdır. DR sıralaması da bu yeni VM’i içerecek şekilde düzenlenmelidir. Şirket içinde önemli bir değişiklik (ofis taşınması, personel değişikliği, tedarikçi değişimi vs.) olduğunda planı gözden geçirin.
Dokümantasyonun güncel kalması, acil durumda ekibin doğru adımları uygulaması için şarttır. Planın hem dijital kopyası hem basılı kopyası kolay erişilebilir ama güvenli bir yerde tutulmalıdır.
Ayrıca, başarılı bir felaket kurtarma kültürü için düzenli eğitimler ve tatbikatlar yapılmalıdır. Yeni ekip üyelerine plan anlatılmalı, tüm ekip yılda en az bir kez temel DR eğitimi almalıdır. Bu sayede, gerçekten bir felaket meydana geldiğinde herkes sakin kalıp prosedürleri uygulayabilir. Unutulmamalı ki felaket kurtarma, sadece teknoloji değil insan ve süreç meselesidir; üçü birden hazır olursa başarı gelir.
Teknik, Stratejik ve Operasyonel En İyi Uygulamalar
Yukarıda detaylı şekilde ele aldığımız konuları, uygulanabilir ipuçları olarak üç ana başlıkta özetleyelim:
Teknik İpuçları
- Doğru Araçları Kullanın: VMware uyumlu bir yedekleme yazılımı tercih edilmelidir. Seçilen çözümün VMware vSphere API’leriyle entegre çalıştığı doğrulanmalıdır. Bu, tutarlı ve hızlı yedeklemeler almanıza yardımcı olur.
- Otomasyonu Benimseyin: Tekrarlanan yedekleme ve kurtarma görevlerini otomatik hale getirin. Otomatik yedekleme zamanlamaları ayarlayın. Örneğin her gece saat 02:00’de tüm kritik VM’lerin artımlı yedeği alınsın. VMware Site Recovery Manager gibi araçlarla otomatik failover senaryoları oluşturun (talimatla tek tıkla DR planını çalıştırmak gibi).
- Yüksek Erişilebilirlik ve Kümelenme: Felaket kurtarma ayrı, yüksek erişilebilirlik ayrıdır ancak bir arada çalışır. VMware ortamınızda HA (High Availability) ve DRS (Distributed Resource Scheduler) özelliklerini aktifleştirin.
Bunlar host bazında arıza toleransı sağlar. Örneğin bir fiziksel sunucu düşerse VM’ler otomatik başka host’ta açılır. Bu, lokal arızaları tolere edip felaket eşiğini yükseltir. - Altyapı Kaynaklarını Planlayın: Yedekleme sunucularınız ve depolama birimleriniz yeterli hız ve kapasiteye sahip olsun. Yedek depolamak için yüksek kapasiteli ve mümkünse deduplication özellikli depolamalar kullanın. Ağ trafiği için yedekleme zamanında kullanılmak üzere bant genişliği planlayın (ör. yedekleme VLAN’ı veya ayrılmış 10 Gbps yedekleme ağı gibi).
- Veri Şifreleme ve Güvenlik: Yedekler hassas veriler içerir. Hem yedekleme yazılımı seviyesinde hem de depolama seviyesinde şifreleme uygulayın. Böylece yedekler yanlış ellere geçerse okunamaz olsun. Ayrıca yedekleme sisteminin erişim yetkilerini kısıtlayın, yalnızca yetkili personel yedeklere erişebilsin.
Stratejik İpuçları
- Politika ve Prosedürler: Yedekleme ve felaket kurtarmayı kurumsal IT politikanızın bir parçası haline getirin. Örneğin, “Tüm yeni kurulan sunucular haftalık yedekleme planına dahil edilir” veya “Kritik değişikliklerden önce snapshot alınır” gibi prosedürleri yazılı hale getirin. Yönetimin bu politikalara onayını alın ki gerek kaynak ayrımı gerek bilinç yaratma açısından destek olsunlar.
- İş Sürekliliği ve DR Ayrımı: Felaket kurtarma planınızı genel iş sürekliliği planlamanızla entegre edin. İş sürekliliği (Business Continuity) sadece IT’nin değil iş birimlerinin de konusudur. Bu yüzden kritik iş birimleriyle görüşüp onların beklentilerini (ör. satış sistemi en geç şu kadar saatte çalışmalı gibi) anlayın ve planı buna göre şekillendirin. Felaket kurtarma, iş sürekliliği planlamasının bir alt kümesi gibi ele alınmalı.
- Dokümantasyon: Planlar, topoloji diyagramları, iletişim listeleri ve uygulama envanteri kapsamlı şekilde dokümante edilmelidir. Bu dokümanların yetkili kişiler tarafından kolayca erişilebilir olması sağlanmalıdır.
VMware ortamının en güncel diyagramı her zaman erişilebilir olmalıdır. Böylece bir sorun anında hangi bileşenin nerede olduğu hızlıca anlaşılır. Dokümanlarda her VM’in hangi hizmeti verdiği, hangi sırayla ayağa kalkacağı, özel kurtarma talimatları varsa (ör. “Önce şu servis start edilecek sonra bu”) belirtilsin. - Üçüncü Parti ve Destek: Kritik altyapınız için tedarikçilerin felaket kurtarma süreçlerine dahil olduğundan emin olun. Örneğin, VMware destek sözleşmeniz varsa acil durumlarda onlara hızlı ulaşma planınız olsun. Felaket durumlarında bulut sağlayıcısından alınacak destek önceden belirlenmelidir. Geçici bulut kaynaklarının kullanımı bu sürece dahil edilebilir.
- Yatırım ve Maliyet Analizi: Stratejik olarak, felaket kurtarma için yapılan yatırımın karşılığını iyi anlatın. Felaket kurtarma planı olmadığında oluşacak iş kaybı finansal olarak ifade edilebilir. DR merkezi maliyetiyle yapılan bu karşılaştırma, yönetime net bir tablo sunar. Genelde büyük felaketler nadiren olur ama olduğunda şirketi kapatma riski bile taşıyabilir – bu mesajı netleştirin.
Operasyonel İpuçları
- İzleme (Monitoring): Hem üretim sistemlerini hem yedekleme süreçlerini sürekli izleyin. VMware vCenter alarmları yanı sıra yedekleme yazılımınızın alarmlarını da kurun. Örneğin, bir yedek başarısız olursa anında IT ekibine e-posta gelsin.
Felaket kurtarma replikasyonu yapıyorsanız (senkron/asenkron), replikasyon gecikmesini izleyin. Eğer normalden fazla artıyorsa müdahele edin (ağ problemine işaret edebilir). - Bakım ve Patch Yönetimi: VMware host’larınızı, vCenter’ınızı ve yedekleme sunucularınızı güncel tutun. Güncel yazılımlar, bilinen hataların ve güvenlik açıklarının kapatılması demektir. Örneğin, VMware ESXi hostlarının versiyon uyumsuzlukları replikasyon veya SRM uyumluluğunu etkileyebilir. O yüzden patch seviyelerini planlı şekilde yönetin.
- Düzenli Tatbikatlar: Daha önce de belirttiğimiz gibi, en az yılda 1 kez kapsamlı DR testi yapın. Yapamıyorsanız bile masa başı senaryoları üç ayda bir ekiple gözden geçirin. Yeni başlayan personel varsa plan üzerinden geçip sorularını cevaplayın.
- Backup ve DR Ayrımı: Operasyonel olarak, günlük yedek alma görevleri ile felaket kurtarma hazırlık görevleri birbirinden farklıdır. İkisine de zaman ve kaynak ayırın.
Örneğin, yedekler günlük olarak alınır ve bu işlem rutin şekilde yürütülür. Felaket kurtarma tatbikatları ise ayrı bir hazırlık süreci olarak her çeyrekte gerçekleştirilir. Bu işleri takvimlerinize koyup unutmadan uygulayın. - Sürekli İyileştirme: Her küçük kesintiden veya hatadan ders çıkarın. Mesela, veri merkezinde yaşanan 1 saatlik bir güç kesintisi sırasında UPS süresinin yetersiz kaldığı anlaşıldı. Bunu DR planına not edin ve gerekirse UPS gücünü artırın veya jeneratör testlerini daha sık yapın.
Bir sunucu arızasında son yedeğin beş gün öncesine ait olduğu fark edilebilir. Bu durum yedekleme sıklığının yetersiz olduğunu gösterir ve politikanın güncellenmesi gerekir.
Yukarıdaki teknik, stratejik ve operasyonel ipuçları, VMware ortamlarınızı daha dayanıklı hale getirmek için yol gösterici olacaktır. Hepsinin ortak noktası proaktif olmak: Felaket yaşanmadan önce hazırlık yapmak, sistemli çalışmak ve iyileştirmeye açık olmaktır.
Makdos ile VMware Yedekleme ve Felaket Kurtarma Çözümleri
Güçlü bir yedekleme ve felaket kurtarma planı oluşturmak önemlidir. Bu planı destekleyecek doğru altyapı ve iş ortağına sahip olmak da aynı derecede kritiktir.
Makdos olarak müşterilerin sunucu ortamlarında veri güvenliğine öncelik veriyoruz. VMware dahil olmak üzere modern yedekleme çözümleri sunuyoruz. Makdos’un sanal sunucu hizmetlerinde performans ve güvenlik temel standartlardır. Entegre yedekleme ve felaket kurtarma özellikleri de bu hizmetlere dahildir.
Düzenli Otomatik Yedeklemeler: Makdos, tüm bulut ve sanal sunucu paketlerinde günlük ve haftalık otomatik yedekleme opsiyonları sağlar. Örneğin, günlük otomatik yedekleme sayesinde VM’ler her gece belirlenen saatte yedeklenir. Bu yedekler güvenli depolama alanlarında saklanır. Bu yedeklere ihtiyaç duyduğunuzda anında erişebilir, tek tıkla geri yükleme yapabilirsiniz.
Manuel snapshot alma imkânı da sunarak, kritik güncellemeler öncesinde kullanıcıların panelden kendi snapshot’unu almasını sağlıyoruz. Böylece olası bir problemde dakikalar içinde sunucunun önceki durumuna dönülmesi mümkün olur.
Hızlı Geri Yükleme ve Yüksek Bant Genişliği: Yedeğin varlığı kadar geri yükleme hızının da önemi büyüktür. Hızlı geri dönüş, kesinti süresini doğrudan etkiler. Makdos altyapısı, 20 Gbps’e kadar uplink bağlantılarıyla çok yüksek veri transfer hızları sunar. Bu sayede büyük boyutlu VMware yedekleri bile geri yüklenirken minimum süre harcanır.
Yedekten dönme işlemi başlatıldığında, güçlü sunucularımız ve ağ altyapımız sayesinde sunucunuz en kısa sürede ayağa kalkar. Yedekleme süreçleri de yüksek bant genişliği sayesinde sunucularınızı yavaşlatmadan arka planda hızlıca tamamlanır.
Coğrafi Yedekleme ve Güvenlik: Makdos, yedekleri farklı coğrafi bölgelerdeki güvenli veri merkezlerinde saklama olanağı sunar. Birincil sunucunuz İstanbul lokasyonunda ise yedeğiniz talep edilirse Ankara veya Avrupa lokasyonlu farklı bir veri merkezinde tutulabilir. Bu coğrafi dağıtım, olası bölgesel bir afette bile yedeklerinizin güvende olmasını sağlar.
Veri merkezlerimiz Tier III standartlarında olup, gelişmiş fiziki ve siber güvenlik önlemlerine sahiptir. Yedekleme depolama alanlarımız RAID korumalı ve düzenli olarak bütünlük kontrolleri yapılmaktadır. Ayrıca tüm yedekler transfer ve bekleme halinde iken güçlü şifreleme algoritmaları ile korunur.
Kesintisiz Veri Merkezi Altyapısı: Makdos’un veri merkezleri ve bulut altyapısı, yedekli enerji ve network tasarımına sahiptir. Bu da yedek alırken veya felaket sırasında yedekten dönerken bir başka kesinti yaşanmaması anlamına gelir.
Örneğin, yedekleme işlemi devam ederken bir hatta problem olursa, ikinci hat devreye girer ve işlem duraksamadan sürer. DR senaryosunda bir veri merkezi devre dışı kalırsa hizmet diğer lokasyondaki altyapı üzerinden sürdürülür.
Veri merkezi replikasyonu ve anlık felaket kurtarma geçişleri konusunda Makdos uzmanlığıyla danışmanlık sunuyoruz. Müşterilere bu süreçlerde doğru mimariyi planlamaları için rehberlik ediyoruz. (Bkz: Veri Merkezi Replikasyonu Nedir? yazımız).
7/24 Teknik Destek: Yedekleme ve felaket kurtarma anlarında en kritik ihtiyaç uzman ekip desteğidir. Bu desteğin her an erişilebilir olması sürecin başarısını belirler. Makdos, 7 gün 24 saat görev yapan teknik destek ekibiyle kritik anlarda yanınızdadır.
Örneğin, gece saatlerinde bir sunucuda sorun yaşanabilir ve yedekten geri dönüş gerekebilir. Destek ekibimiz süreci hızlıca devreye alarak uçtan uca izler. Geri yükleme sırasında karşılaşacak sorunlara (ör. bozulan bir dosya sistemi, eksik konfigurasyon gibi) anında müdahele edilerek çözüme kavuşturulur.
Proaktif izleme sayesinde, müşterimiz fark etmeden önce bile bazı problemleri tespit edip çözebiliyoruz. Bu sayede, Makdos üzerinde çalışan VMware ortamlarınız güçlü bir altyapıyla korunur. Uzman ekip desteği de bu güvenceyi tamamlar.
Kullanıcı Dostu Kontrol Paneli: Makdos müşterileri için geliştirdiğimiz kontrol paneli, yedekleme işlemlerinin takibini ve yönetimini oldukça kolaylaştırır. Web arayüzümüzden sunucunuzun son alınan yedeklerini görebilir, istediğiniz yedeği birkaç tıkla geri alabilirsiniz. İsterseniz yedek indirme özelliği ile yedek dosyanızı harici olarak indirebilir, kendi saklamak istediğiniz bir ortamda tutabilirsiniz.
Planlamış olduğunuz yedekleme zamanlamalarını panelden değiştirebilir, anlık ihtiyaçlar için hemen yeni bir yedek al komutu verebilirsiniz. Tüm bu işlemler, teknik bilgi düzeyi ne olursa olsun anlaşılır ve basit adımlarla yapılabilir.
Makdos, Türkiye’de iş sürekliliği ve veri güvenliği konusunda birçok işletmeye çözüm ortağı olmuş, güvenilir bir firmadır. Özellikle KOBİ’lere uygun felaket kurtarma ve bulut yedekleme çözümleri sağlıyoruz. Her ölçekte işletmenin verilerini korumasına yardımcı oluyoruz.
VMware ortamınız için altyapı gücümüzle desteklenen yedekleme ve felaket kurtarma çözümleri sunuyoruz. Yaygın veri merkezi ağımız ve uzman ekibimiz iş sürekliliğini güvence altına alır. VMware altyapınızın yedekleme ve felaket kurtarma yapısını güçlendirmek istiyorsanız doğru yerdesiniz. Makdos uzman ekibiyle iletişime geçerek süreci hemen başlatın.
Sonuç
Bu rehberde, VMware ortamlarında yedekleme ve felaket kurtarma süreçleri incelendi. Konu, teknik detaylar ve pratik kullanım senaryolarıyla desteklendi. Doğru yedekleme ve felaket kurtarma yaklaşımları işletmeler için güçlü bir güvence sağlar. Uzun kesintiler ve veri kayıpları bu yapı sayesinde önlenir.
Özetlemek gerekirse bu yazıda şunları öğrendiniz:
- VMware sanallaştırma altyapısında yedekleme yapmanın önemini ve snapshot gibi araçların doğru kullanımını,
- 3-2-1 gibi en iyi uygulamalarla yedeklerin nasıl güvenceye alınacağını ve düzenli testlerle veri bütünlüğünün nasıl doğrulanacağını,
- Felaket kurtarma planının adımlarını, RPO/RTO kavramlarının işinizi sürekliliği için nasıl hedefler belirlediğini,
- Replikasyon, ikinci bir felaket kurtarma sitesi ve NSX gibi teknolojilerin DR planındaki rolü,
- Makdos’un yedekleme çözümleriyle VMware ortamlarınızın nasıl ek bir güvenlik katmanına kavuşacağını.
Artık felaket gelmeden önce atacağınız adımların, felaket sonrasında şirketinizin ayakta kalması için belirleyici olduğunu biliyorsunuz.
Unutmayın: Yedekleme ve felaket kurtarma bir maliyet değil, aksine işinizi sigortalayan bir yatırımdır.
Şimdi siz de sistemlerinizi gözden geçirip burada paylaşılan en iyi uygulamaları hayata geçirebilir, veri merkezinizin dayanıklılığını artırabilirsiniz.
VMware altyapınızda yedekleme ve felaket kurtarma yapısını güçlendirmek istiyorsanız doğru adrestesiniz. Makdos uzmanlarıyla iletişime geçerek süreci hemen başlatın.
Verilerinizi güvenle korumak için doğru yedekleme ve DR çözümünü seçebilirsiniz. Detaylar için Makdos Sunucu Hizmetleri sayfamızı inceleyin.














